High Performance Computing Cluster Documentation at The Wistar Institute
Welcome to the documentation site for the Wistar HPC Cluster. This documentation is designed to to provide guidance and insight needed to navigate and leverage the capabilities of The Wistar Institute's HPC cluster.
To provide feedback on the wi-hpc cluster please fill out this form.
Please see our News page for recent updates and announcements.
About the HPC Cluster
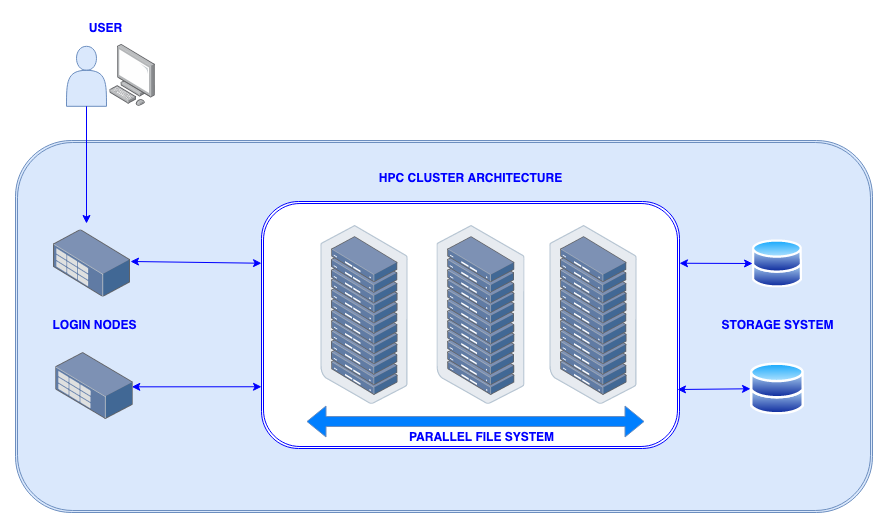
A high performance computing (HPC) cluster is a collection of networked computers and data storage. Individual servers in this cluster are called nodes. Our cluster are only accessible to researchers remotely; your gateways to the cluster are the login nodes. From these nodes, you view files and dispatch jobs to other nodes across the cluster configured for computation, called compute nodes. The tool we use to manage these jobs is called a job scheduler. All compute nodes on a cluster mount a shared filesystem; a file server or set of servers store files on a large array of disks. This allows your jobs to access and edit your data from any compute node. See our summary of the hardware and resources we maintain, to understand the details of each component at Wistar.
Key Changes
Scheduling Prioritization Changes
The new cluster will leverage Slurm's FairShare algorithm to determine the priority of jobs in the queue. THe old system utilized a First In First Out (FIFO) policy, with the option to backfill for small jobs. The new priory system will decrease the priority of users who have consumed lots of resources to ensure that all users get their "fair share" of resources.
Resource Allocations
The new cluster will now restrict users workloads by CPU and Memory using Linux CGroups to ensure that users jobs will not expand beyond requested/allocated resources. Jobs that exceed memory requirements will now receive an Out Of Memory (OOM) error and be automatically killed. These constraints will ensure that one users job on a node do not interfere with another users jobs.
Getting Help
To get help, report issues, or ask questions please see Getting Help. Where applicable, please include the following information:
- Your username
- Job ID(s)
- Error messages
- Command used to submit the job(s)
- Path(s) to scripts called by the submission command
- Path(s) to output files from your jobs